How to design pricing for AI APIs and LLM-powered products

Guides
Read time: 11 min

Arnon Shimoni
✓ Expert opinion
AI API pricing comes down to six decisions, in order: what to meter, which primitive to charge for, what to charge per unit, how to structure tiers, hard cap or soft cap, and how the credit wallet behaves. This guide walks through each one with worked examples and dollar amounts. There’s a Claude prompt at the end you can paste in to diagnose your own pricing.
The reason for writing this blog post is because I was talking to a founder who showed me his pricing page, which said “$0.02 per 1k tokens”… I asked what the customer sees on the invoice, and… I didn’t like the answer. So, this is for founders, PMs, and monetization leads about to make the decisions that will haunt the next 18 months of their P&L.
The structure of an AI pricing plan
With classic API pricing, a plan is the subscription tier (Free, Pro, Scale).
Inside each plan there are phases (a 14-day trial, then the default phase) that make it up.
Inside each phase there are rate cards that tie a meter to a price and an entitlement. During a trial, you may get more features than during the “evergreen” phase.
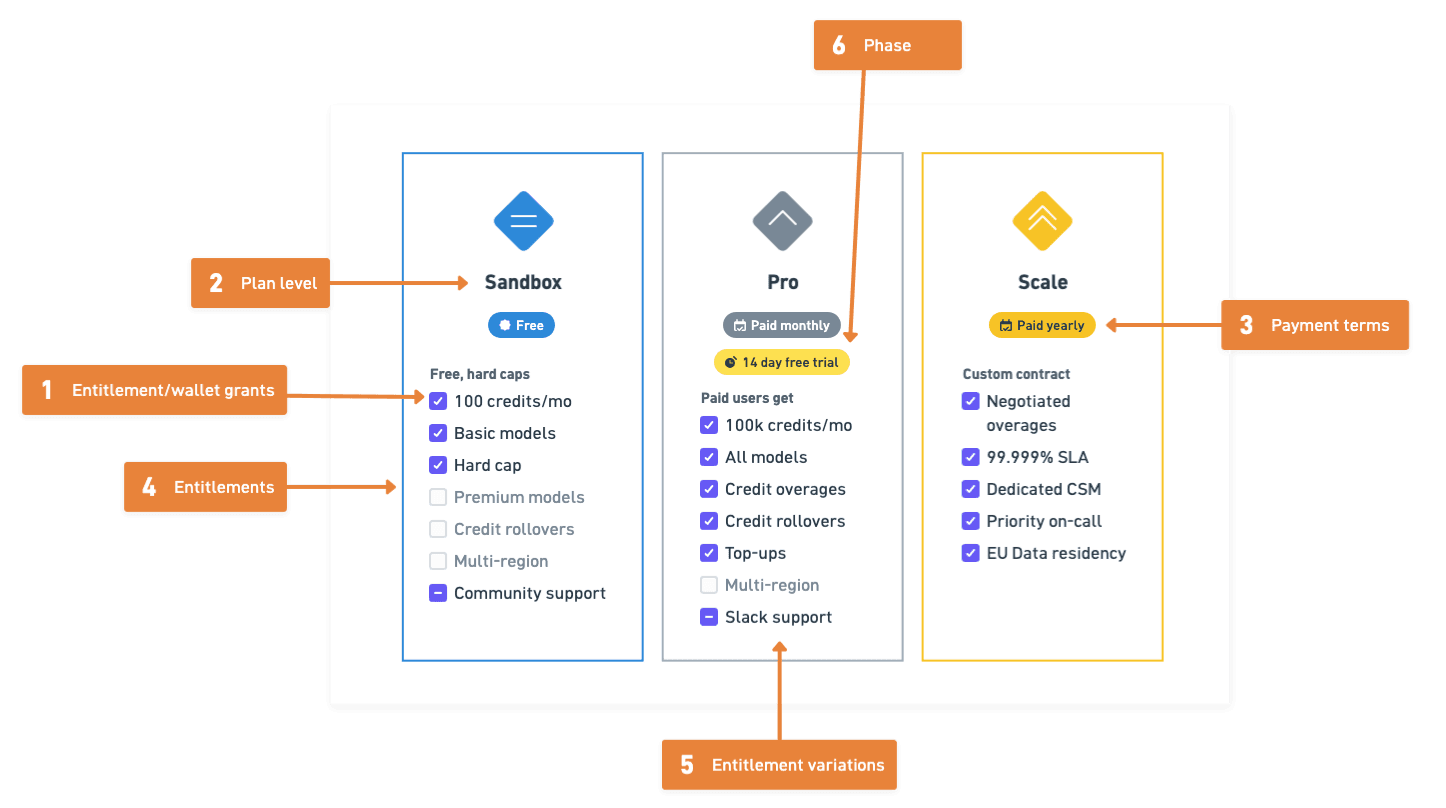
AI pricing adds three twists to this structure.
The meter is no longer just “requests.” It’s tokens (input and output), credits (abstracted units), or outcomes (a completed task, a resolved ticket, a generated document).
The rate card has to handle multiple model costs sitting under one customer-facing price.
The entitlement is a wallet, not a counter. Credits accumulate, expire, roll over, and get spent across multiple features.
Also, phases matter more than they did in classic SaaS, because AI pricing changes more often. A model provider cuts their price or you ship a new credit rate, or a customer extends their trial - all of those creates a phase transition, not necessarily just a contract amendment.

That gives you six decisions, in order.
Step 1: Pick what you’re metering
The meter is the thing you count. Pick it wrong and you’ll fight your customers about whether the bill is fair for the next two years.
For AI products, four meters dominate:
Input + output tokens (OpenAI, Anthropic, Mistral)
Credits (Cursor, Notion AI, Linear AI)
Outcomes (Intercom Fin at $0.99 per resolved conversation)
Compute time
The meter has to correlate with two things at once: customer-perceived value, and your cost of goods. A flat per-request meter on a multi-model product will wreak havoc on your (already thin) gross margin the moment a customer sends 50k-token prompts.
💡 Decision to lock: which meter, with the exact definition.
Write it down - “1 token = 1 GPT-5.5-style token, input + output combined”. My exprience is that vague definitions are a source of customer disputes that you can very easily avoid.
Step 2: Pick your pricing primitive
I suggest a customer-facing unit, even if you do the math in another internally.
Primitive | What you charge for | When it works well | When not to use it |
|---|---|---|---|
Token | Input + output tokens at a $/1k rate | Direct API products, technical buyers, OpenAI-style resellers | Multi-model usage, when output volume varies wildly, non-technical buyers |
Credit | Abstracted units redeemable against any feature | LLM-powered SaaS, mixed model usage, packaged AI features | When credit rates don’t track cost changes, when customers can’t predict burn rate |
🏆 Outcome | Per generated document, resolved ticket, completed task | Clear value units, enterprise contracts, vertical AI | When outcome definitions are fuzzy, when failure modes aren’t priced in |
Most products that do well in a pricing change end up running all three at once.
For example, a per-token for power users on the API, with credits for the packaged product, and outcome pricing on top for enterprise deals.
Agentforce charges for conversation, Fin runs outcome-based, but cursor runs credits and OpenAI runs tokens. All are valid, but highly dependent on the business.
So again, outcomes first if you can define them, credits second for flexibility, tokens last if you can’t avoid them.
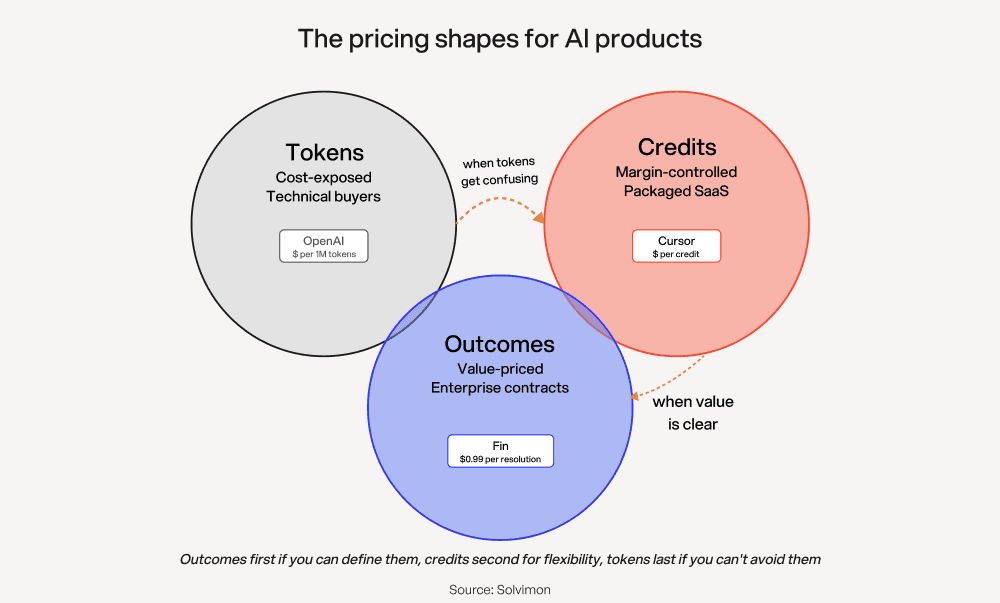
💡 Decision to lock: which primitive appears on the invoice.
Step 3: Calculate your cost and set your price
Here’s a good example to work with: Your product makes one Claude Opus 4.8 call per user request. Anthropic charges $5 per 1M input tokens and $25 per 1M output tokens.
If your average request uses 1k input tokens and 500 output tokens, your cost per request is $0.005 + $0.0125 = $0.0175.
Three pricing approaches from that cost to consider:
Cost-plus markup. Charge $0.035 per request. 50% gross margin. Predictable, defensible, boring. Works in the API reseller category. Breaks the moment you add a second model with a different cost profile.
Value-based. The customer would pay $1 per generated document because that’s the value to them. Charge $0.50. ~96.5% gross margin. Risky when a competitor undercuts you. Excellent when you have a moat. (The classic Salesforce play. Different now in AI because the moat is thinner.)
Credit-based abstraction. Define a credit as “one standard request” and charge $0.05 per credit. Heavy-input requests cost 2 credits. Document generation costs 5 credits. The customer sees a balance, not a token count. Your margin moves smoothly across model changes because you control the credit-to-cost mapping internally.
Side-note: Opus 4.7 introduced a new tokenizer that can use up to 35% more tokens for the same input text compared to earlier Opus models. Same prompt, same model family can result in a 35% bigger bill. If your pricing is per-token, you just absorbed a price hike you can’t pass through easily but if your pricing is per-credit, you adjust the credit-to-token ratio internally and the customer notices nothing. Credits as architecture, again.
A practical rule for me is that if you can’t predict the customer’s monthly bill within ±20%, your pricing is too tightly coupled to your cost. Credits with controlled rates kinda solve it, while cost-plus per-token definitely doesn’t.
💡 Decision to lock: per-unit price (in whatever primitive you picked) and target gross margin.
Step 4: Build your tier structure
Most AI products land on 4-5 tiers. The structure matters more than the numbers. You can change the numbers. You can’t easily change the shape.
Here’s a starting point to consider:
Tier | Price/mo | Included | Limit type | Best for |
|---|---|---|---|---|
Sandbox | $0 | 100 credits/month | Hard cap | Devs evaluating, demos |
Starter | $29 | 5,000 credits/month | Soft cap, $0.01/credit overage | Indie devs, early prod |
Pro | $299 | 100,000 credits/month | Soft cap, $0.005/credit overage | Growing teams, full prod |
Scale | From $2,500 | Annual commit, custom volume | Negotiated overage | $1M+ ARR mid-market |
Enterprise | Custom | Custom + SLA + multi-entity | Custom | Regulated, multi-region |
I like a hard cap on free (protects margin from abuse), or a soft cap with overages on paid (let customers scale), and commit-based for the top.
You should note, that a free tier is typically an acquisition cost - so price it for the abuse boundary… 100 credits gets a developer through a “hello world” and 10,000 credits can get a hobbyist building real things on your dime. That’s fine if you’re planning for it, but the abuse line is wherever the cost per signup makes your CAC start to really hurt.
Also worth noting that charging 2-3x the included rate as overage is standard. Going higher than 3x makes customers hard-cap their own usage internally which suppresses your expansion revenue and may sabotage your product (it feels like you’re robbing them). Going lower than 1.5x definitely leaks margin on power users.
💡 Decision to lock: tier count, included usage per tier, price per tier, overage rate per tier.
Step 5: Decide hard cap vs soft cap
Hard limits block requests when the entitlement is exhausted. Customers get an error (consider an HTTP 429!) and stop until they upgrade or the period rolls over.
Soft limits let usage continue past the entitlement and bill the overage at the period boundary.
Use hard limits on:
Free tiers and trials
Anything where the customer hasn’t agreed to overage terms
Developer sandboxes and test environments
Use soft limits on:
Paid tiers where overage terms are in the contract
Anything where blocking would break a production system
Scale and Enterprise customers who want to maximise usage and have credit lines
The common mistake I see people make is putting hard limits on paid tiers because “we don’t want to surprise the customer and have their app stop working” - which is noble but getting a huge huge bill at the end of the month isn’t great either. A soft limit with a generous spend alert is the move.
💡 Decision to lock: hard or soft per tier, the overage price for soft, the alert thresholds (50%, 80%, 100% of entitlement).
Step 6: Design your credit wallet
If your primitive is credits (Step 2), the wallet is the entire pricing experience. Get the four decisions wrong and customers will tolerate you but never trust you.
Expiry
Do credits expire? Month-end is harsh, year-end is generous, contract-end is the enterprise default.
Having no expiry creates a pretty serious liability on your balance sheet - so talk to a CFO before you ship “credits never expire” as a marketing line.
Rollover
What happens to unused credits at period boundaries? Full rollover is most user-friendly, but some do a partial rollover.
Having no rollover sucks. Customers will eventually notice and resent it.
Top-ups
Can customers buy more mid-cycle?
At the same price, or a premium?
Self-serve, or sales-assist?
Top-ups are where customer happiness lives. Friction here is the single biggest cause of “we love the product but the billing is annoying.”
Multi-meter redemption
Can one credit pool be spent across multiple features (chat, search, generation)? Or does each feature have its own pool?
A single pool is friendlier and easier, but a multi-pool is easier to revenue-recognize under ASC 606. You’ll end up with single pool because customers ask for it.
💡 Decision to lock: expiry policy, rollover policy, top-up flow, single vs multi pool.
Planning for when the model prices drop
Anthropic took Opus from $15 input / $75 output per 1M tokens (Opus 4.1) to $5 / $25 (Opus 4.5 and later). A 3x cut on the most premium model in the lineup.
OpenAI ships similar moves every quarter, and… Yeah, well, it’s hard to plan around this.
If you priced per-token at a fixed markup, your gross margin just tripled. Good for the P&L, but not great for the customer who now feels the bill is too high.
Expect a renegotiation request within 60 days, or a switch to a vendor who reprices automatically.
If you priced credit-based, you have a choice. Hold the credit rate and bank the margin. Lower it and pass savings through. Or rebalance: lower the rate for older models, hold for newer ones.
If you priced outcome-based, you barely notice. The customer pays $0.99 per resolution whether you used Opus 4.7 or Haiku 4.5. Margin compounds automatically. (Why outcome pricing is the most durable shape, and the hardest to ship on day one.)
The infrastructure question you must know is can your billing system change a credit rate mid-cycle without rewriting prior invoices? If not, every model price drop becomes a project and a migration which can really hurt.
Diagnose your pricing with Claude
Copy this prompt into Claude (or any capable model). It runs the discovery with you and returns a tier table and reasoning. It won’t get the price points exactly right. That’s your judgment and your data. It does get the shape right, and it saves 60 days of design work.
Run it once, refine the inputs, run it again - because the second pass is usually better!
What billing infrastructure has to handle
5 things that we’ve seen really hurt with AI pricing if you didn’t design for them:
Per-event metering at high cardinality. Millions of events per day. Aggregating at month-close doesn’t scale.
Credit wallets as first-class entities. Not invoices with line items. Wallets with balances, debit/credit history, expiry, rollover, and multi-meter redemption rules.
Real-time balance updates. Customers want to see credits drop as they use the product. If your system updates nightly, they’ll build their own UI on top of your API. Or churn.
Margin visibility at the unit level. Per-customer, per-feature, per-model cost-vs-revenue, in a dashboard the finance team can actually read.
Rate-card versioning. You’ll change credit rates 3-5 times in the first year. Your billing system has to handle “this customer was on the old rate until July 15, new rate from July 16” without rewriting February’s invoice.
Solvimon treats credits and wallets as first-class billing primitives, which is different from gluing a metering service to a subscription billing tool and writing the wallet logic yourself.
Frequently Asked Questions
How do I price AI tokens?
Calculate your cost per request from the model provider’s per-token rates, multiply by your expected input and output tokens per request, and apply either a cost-plus markup, a value-based price, or a credit abstraction. Credit abstraction is more durable across model price changes.
Should I let credits expire?
Yes, with a long enough horizon. 12 months or contract-end is standard. No expiry creates a growing balance-sheet liability. Aggressive expiry (monthly) feels like a gift-card scam and erodes trust at renewal.
When should I use a hard cap vs a soft cap?
Hard cap on free tiers, trials, and developer sandboxes. Soft cap on paid tiers, production workloads, and Enterprise contracts. Hard cap on a paid production tier is the most common mistake. Customers would rather pay an overage than have their app go down.
How many tiers should I have?
Three to five. Sandbox (free), Starter, Pro, Scale, optional Enterprise. More than five and the pricing page stops being a decision aid and starts being a maze.
How do I handle multiple AI models with different costs?
Either pass the cost variance to the customer (different credit rates per model), or absorb it internally (fixed credit rate, smart routing to the cheapest qualifying model). Absorbing it requires a billing system that supports credit-to-cost mapping at the route level.
How do credits get revenue-recognized under ASC 606?
Credits are typically recognized as revenue when consumed (the performance obligation is satisfied at redemption), not when sold. Unredeemed credits sit on the balance sheet as deferred revenue. Breakage (unredeemed credits at expiry) is recognized as revenue at expiry, subject to your historical breakage rate analysis. Ask your auditor before you finalize the wallet policy.
Related
AI agent pricing. How vendors charge for autonomous agents, and where it differs from paying per token.
How to design usage-based pricing. A step-by-step approach to picking meters, units, and rates.
Solvimon for AI. Billing infrastructure built for token, credit, and hybrid pricing.
Ready for billing v2?
Solvimon is monetization infrastructure for companies that have outgrown billing v1. One system, entire lifecycle, built by the team that did this at Adyen.




